String类型在Java语言中算是比较特殊的一种类型,它区别于8种基本数据类型(int,short,byte,long,double,float,char,boolean)。这些基本数据类型对应的包装类型大多都提供了常量池(除了Double,Float,常量池范围-128,127,其中Integer可以通过JVM参数-XX:AutoBoxCacheMax调节常量池的范围)。String类型的常量池相对比较特殊,它的使用方法主要有两种。
- 直接用双引号声明出来的 String对象 会直接分配在存储在字符串常量池里面
- 如果不是用双引号声明的 String对象,可以调用String对象的intern方法。intern方法会检查字符串常量池里面是否存在当前字符串,如果不存在就会把该字符串存储在常量池里,存在则直接返回该字符串的引用。以下就是JDK1.8中String#intern方法的注释。
1 | * When the intern method is invoked, if the pool already contains a |
String#intern方法详解
它的大体实现结构就是: JAVA 使用 jni 调用c++实现的StringTable的intern方法, StringTable的intern方法跟Java中的HashMap的实现是差不多的, 只是不能自动扩容。默认大小是1009。
要注意的是,String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找)。
在 jdk6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。在jdk7中,StringTable的长度可以通过一个参数指定:
-XX:StringTableSize=99991
相信很多 人都做过类似 String s = new String("abc")这个语句创建了几个对象的题目。 这种题目主要就是为了考察对字符串对象的常量池掌握与否。上述的语句中是创建了2个对象,第一个对象是”abc”字符串存储在常量池中,第二个对象在JAVA Heap中的 String 对象。
来看一段代码:
1 | public static void main(String[] args) { |
打印结果是
- jdk6 下
false false - jdk7 下
false true
jdk1.6原因:
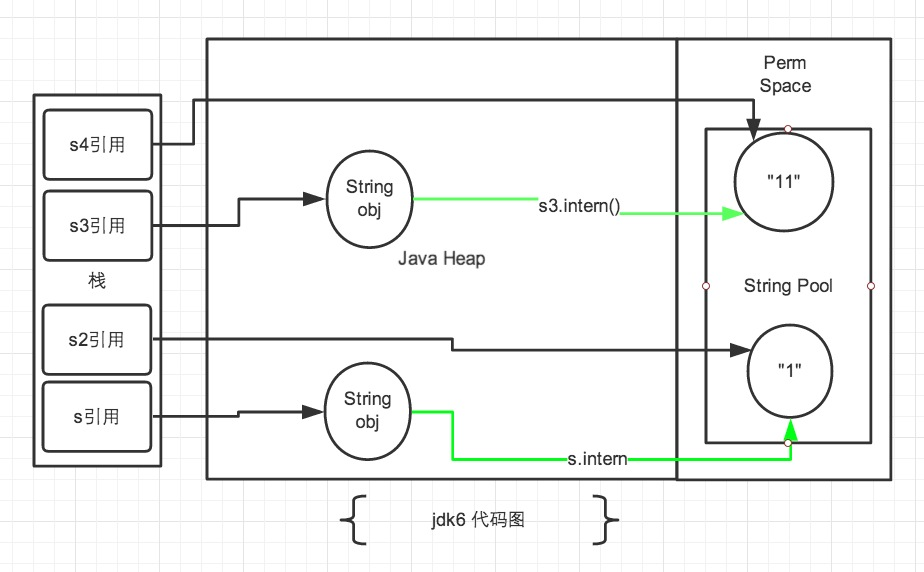
注:图中绿色线条代表 string 对象的内容指向。 黑色线条代表地址指向。
如上图所示。首先说一下 jdk6中的情况,在 jdk6中上述的所有打印都是 false 的,因为 jdk6中的常量池是放在 Perm 区中的,Perm 区和正常的 JAVA Heap 区域是完全分开的。上面说过如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 JAVA Heap 区域。所以拿一个 JAVA Heap 区域的对象地址和字符串常量池的对象地址进行比较肯定是不 相同的,即使调用String.intern方法也是没有任何关系的。
然后将s3.intern();语句下调一行,放到String s4 = "11";后面。将s.intern(); 放到String s2 = "1";后面。是什么结果呢
1 | public static void main(String[] args) { |
打印结果为:
- jdk6 下
false false - jdk7 下
false false
jdk1.7原因:
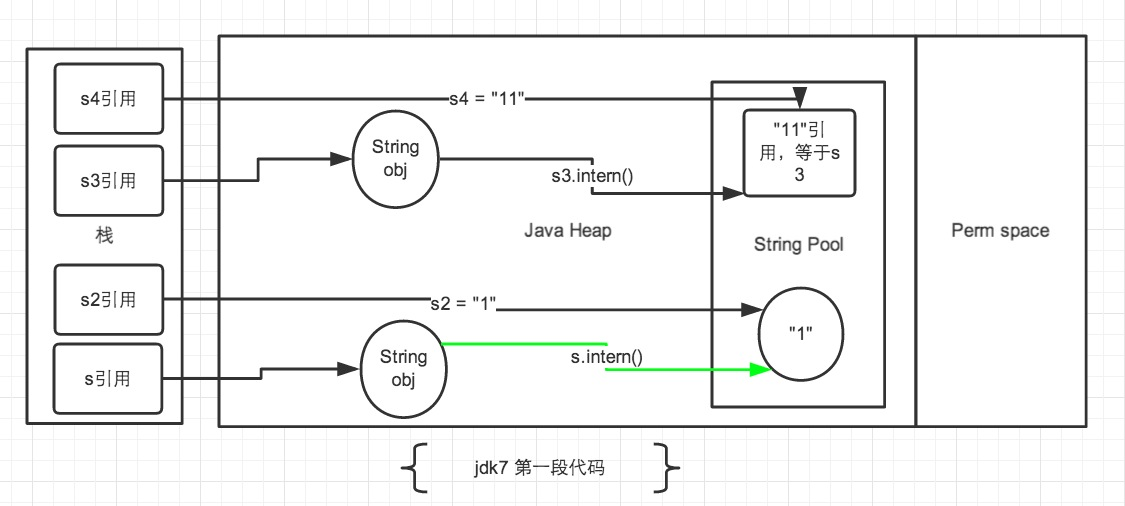
- 在第一段代码中,先看 s3和s4字符串。
String s3 = new String("1") + new String("1");,这句代码中现在生成了2最终个对象,是字符串常量池中的“1” 和 JAVA Heap 中的 s3引用指向的对象。中间还有2个匿名的new String("1")我们不去讨论它们。此时s3引用对象内容是”11”,但此时常量池中是没有 “11”对象的。 - 接下来
s3.intern();这一句代码,是将 s3中的“11”字符串放入 String 常量池中,因为此时常量池中不存在“11”字符串,因此常规做法是跟 jdk6 图中表示的那样,在常量池中生成一个 “11” 的对象,关键点是 jdk7 中常量池不在 Perm 区域了,这块做了调整。常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用指向 s3 引用的对象。 也就是说引用地址是相同的。 - 最后
String s4 = "11";这句代码中”11”是显示声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。所以 s4 引用就指向和 s3 一样了。因此最后的比较s3 == s4是 true。 - 再看 s 和 s2 对象。
String s = new String("1");第一句代码,生成了2个对象。常量池中的“1” 和 JAVA Heap 中的字符串对象。s.intern();这一句是 s 对象去常量池中寻找后发现 “1” 已经在常量池里了。 - 接下来
String s2 = "1";这句代码是生成一个 s2的引用指向常量池中的“1”对象。 结果就是 s 和 s2 的引用地址明显不同。图中画的很清晰。
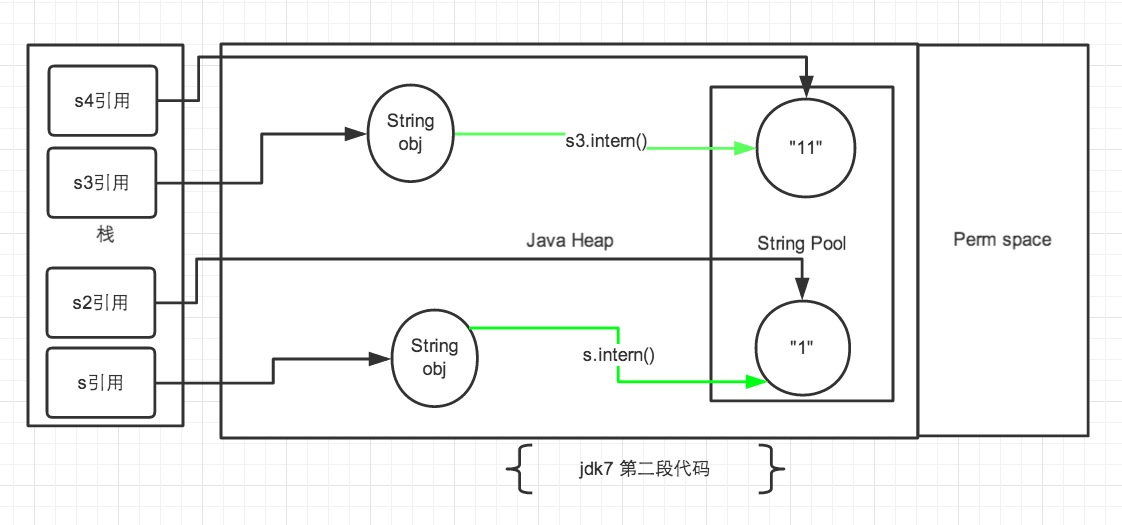
- 来看第二段代码,从上边第二幅图中观察。第一段代码和第二段代码的改变就是
s3.intern();的顺序是放在String s4 = "11";后了。这样,首先执行String s4 = "11";声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象。然后再执行s3.intern();时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。 - 第二段代码中的 s 和 s2 代码中,
s.intern();,这一句往后放也不会有什么影响了,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s 和 s2 的引用地址是不会相等的。
总结
从上述的例子代码可以看出 jdk7 版本对 intern 操作和常量池都做了一定的修改。主要包括2点:
- 将String常量池 从 Perm 区移动到了 Java Heap区
String#intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。